Reliability refers to the consistency of measurement. If the measurement were to be done more than one time or more than one person on the same phenomenon, and it produces the same results. The measurement is reliable. There are four aspects of reliability (https://www.socialresearchmethods.net/kb/reltypes.php).
1) Inter-rater or Inter-observer reliability - This type of reliability used to assess the agreement between/among observers of the same phenomenon.
2) Test-retest reliability - This type of reliability will be used when we administer the same test/instrument to the same sample on two different times.
3) Inter-method reliability - This type of reliability will be used to assess the degree to which test scores are consistent when there is a variation in the methods or instruments used. When two tests constructed in the same way from the same content domain, it may be termed "parallel-forms reliability".
4) Internal consistency reliability - This type of reliability will be used to assess the consistency of results across items within a test.
For the scale development, reliability of an instrument refers to the degree of consistency or the repeatability of an instrument with which it measure the concept it is supposed to be measuring (Burns & Groove, 2007). The reliability of an instrument can be assessed in various ways. Three key aspects are internal consistency, stability, and equivalence.
Validity
Validity refers to the credibility of the measurement. The measurement can measure what it want to measure. There are two aspects of validity.
1) Internal validity. It refers that the instruments or procedures used in the study measure what they are supposed to measure.
2) External validity. It refers that the results of the study can be generalized.
For the scale development, validity is inferred from the manner in which a scale was constructed, its ability to predict specific events, or its relationship to measure of other constructs (DeVellis, 2012). There are three types of validity: content validity, construct validity, and criterion-related validity.
The relationships between reliability and validity
If measurements are valid, they must be reliable. The developed scale is expected to contain evidence to support its reliability and validity.

Sensitivity and Specificity
Sensitivity is the extent to which true positives that are correctly identified (so false negatives are few). For example: A sensitive test helps rule out disease. If a person has a disease, how often will the test be positive (true positive rate)?
Specificity is the extent to which positives really present the condition of interest and not some other condition being mistaken for it (so false positives are few). For example: If a person does not have disease, how often will the test be negative (true negative rate)?
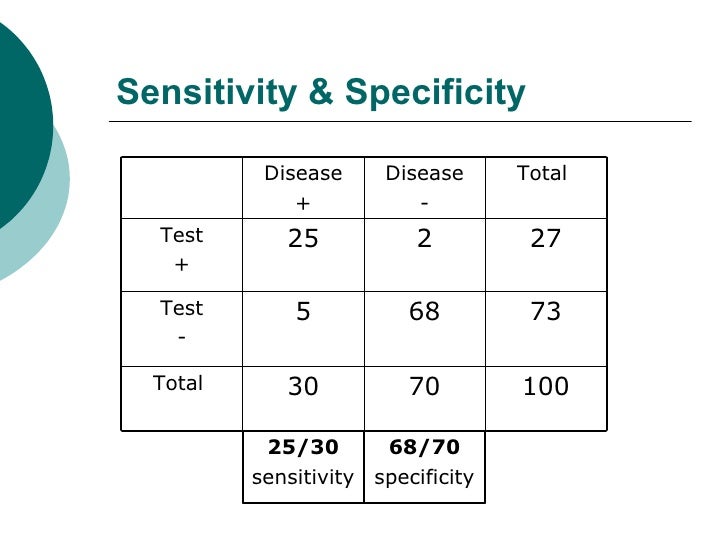
For example, the results of testing TB from 100 subjects,
ROC curve
The measures of sensitivity and specificity rely on a single cutpoint to classify a test result as positive or negative. In many diagnostic situations the results of a continuous test or ordinal predictor, there are multiple cutpoints. A receiver operating characteristic curve (ROC curve) is an effective method of evaluating the performance of diagnostic tests.


References:
Burns, N., & Groove, S. K. (2007). Understanding nursing research: building an evidence-based practice (4th ed.). St. Louis, Missouri: Sanders Elsevier.
DeVellis, R. F. (2012). Scale development: theory and applications (3rd ed.). Los Angeles: SAGE Publications.



No comments:
Post a Comment